Get maximum out of your LLM by Using Context Caching
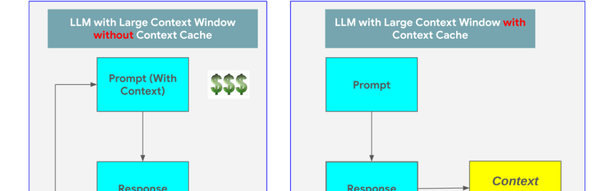
Google recently announced a game-changing feature for Large Language Models (LLMs): context caching. This innovation significantly enhances the efficiency and scalability of LLMs, allowing them to process information more effectively and cost-effectively. But what exactly is context caching, and how does it work? Think of an LLM like a human