Get maximum out of your LLM by Using Context Caching

Google recently announced a game-changing feature for Large Language Models (LLMs): context caching. This innovation significantly enhances the efficiency and scalability of LLMs, allowing them to process information more effectively and cost-effectively.
But what exactly is context caching, and how does it work?
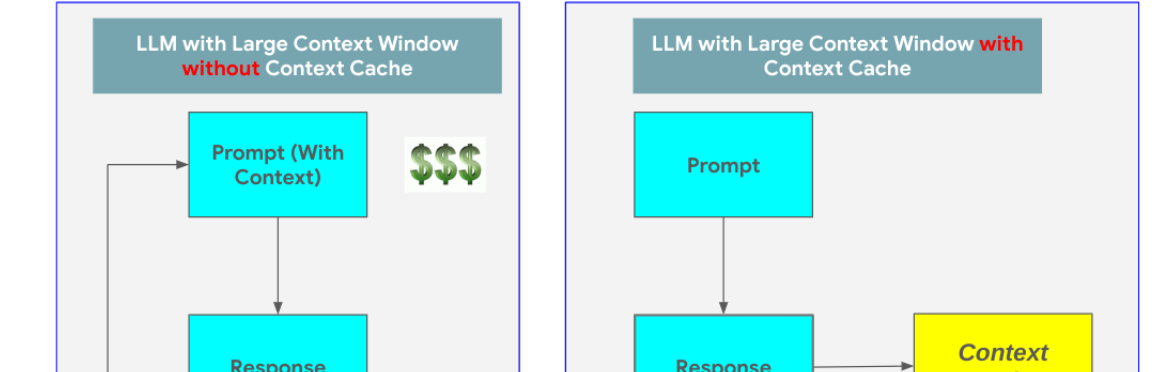
Think of an LLM like a human brain. It has a "working memory" – the context window – where it holds the information it's actively processing. A larger context window allows the LLM to grasp more data at once, enabling a deeper understanding and more coherent responses. But even the most powerful brain has limits to its working memory.
This is where context caching acts as the LLM's "long-term memory." It's a separate storage space where the LLM can store and retrieve previously processed information. When faced with a question related to something it has encountered before, the LLM can swiftly access the relevant information from the cache, eliminating the need to re-process the entire dataset.
Why is this important?
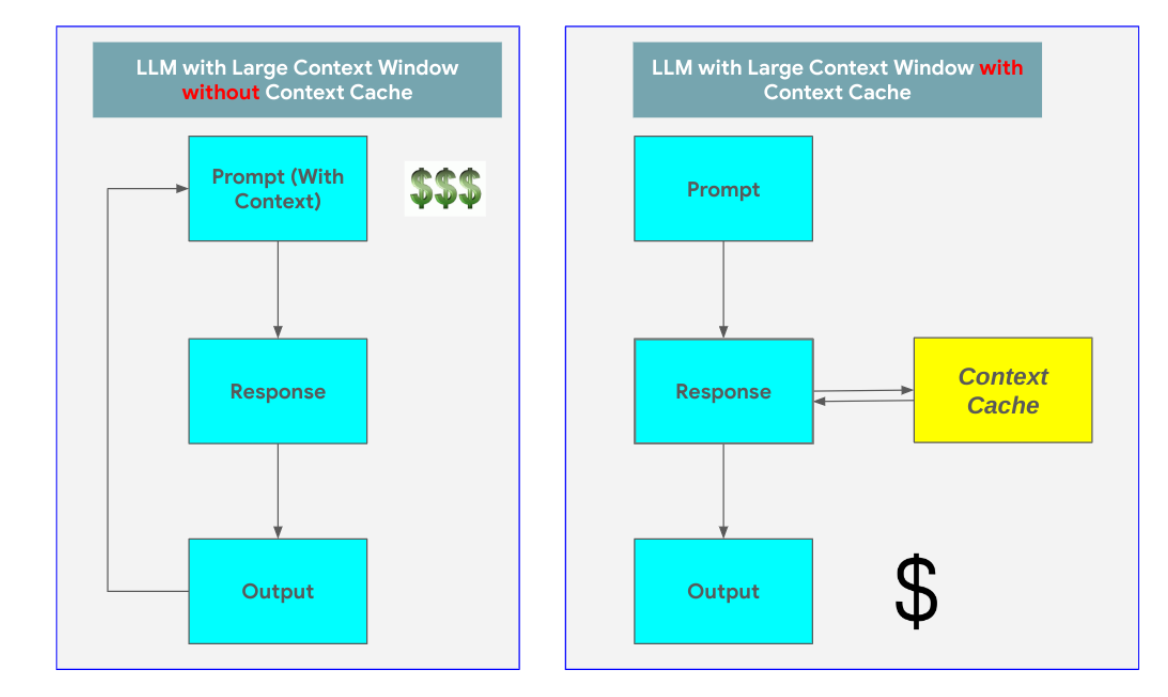
Imagine uploading a lengthy document to an LLM and asking it a series of questions. Without context caching, the LLM would need to re-analyze the entire document for every single question, even if it's about a small detail. This is like rereading a whole book every time you want to recall a specific paragraph – incredibly inefficient and time-consuming!
With context caching, the LLM processes the document once and stores its essence in the cache.
When you ask a question, it retrieves the relevant information from the cache, answering your query without the overhead of re-processing. This translates to:
- Reduced processing time: Faster responses and improved user experience.
- Lower cost: Significant savings by avoiding redundant processing.
- Improved scalability: Handling larger datasets and more complex queries with ease.
A Real-world Example: Streamlining Customer Support
Consider an LLM-powered chatbot handling customer support inquiries. A customer starts a conversation, detailing a complex issue and referencing past interactions with the company.
- Large Context Window: The LLM uses its extensive context window to understand the customer's current query within the broader context of their history with the company. This enables the chatbot to provide personalized and relevant support.
- Context Caching: The LLM stores the entire conversation history in its cache. When the customer returns with a follow-up question, the chatbot instantly retrieves the relevant context, even if it's no longer in the active context window. This ensures seamless continuity and efficient problem resolution without re-processing past interactions.
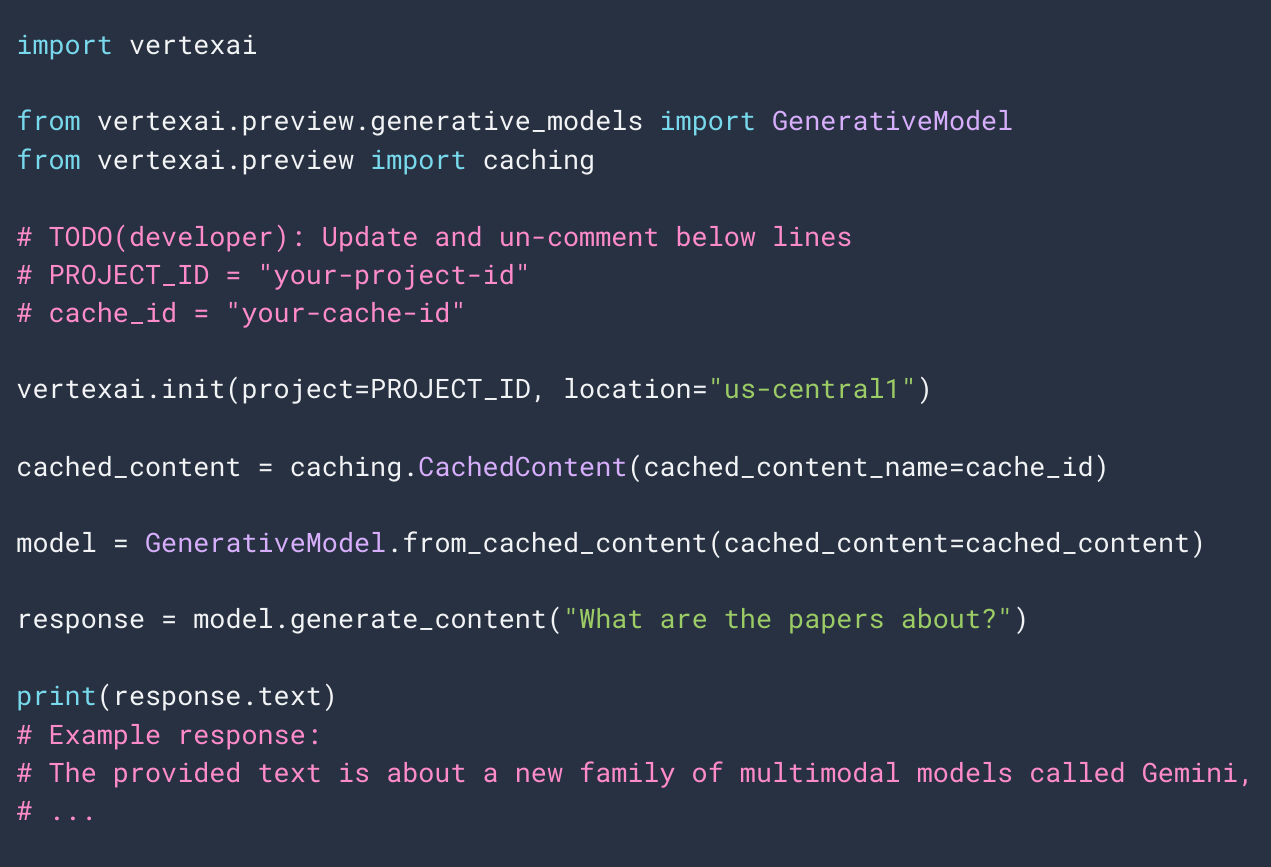
Here is a sample code on how you would combine the both:
The Power of combining both
The combination of a large context window and context caching creates a powerful synergy. The large context window provides a holistic understanding, while context caching allows for efficient and targeted retrieval of specific information. This results in LLMs that are faster, more cost-effective, and capable of handling increasingly complex tasks.
Leverage context caching to minimize expenses on requests that have recurring content with substantial input tokens. You can reuse cached context items, like extensive text, audio files, or video files, in prompt requests to the Gemini API to produce output. Each prompt request that utilizes the same cache also incorporates text specific to that prompt. For instance, every prompt request that forms a chat conversation could include the same context cache referencing a video, along with unique text that makes up each turn in the chat. The minimum size for a context cache is 32,768 tokens.
By leveraging the power of context caching, businesses can unlock the full potential of LLMs, enhancing customer experiences, optimizing operations, and driving innovation across various domains
Thank you for reading through as always! Let me know if you have any comments or feedback

