Are We Ready for Responsible AI in Marketing? (Video Inside)


In addition to the article, I've included a video to break down the subject matter in a more engaging way. I hope you find it helpful! Requesting you to please comment, so that I can understand if it was beneficial
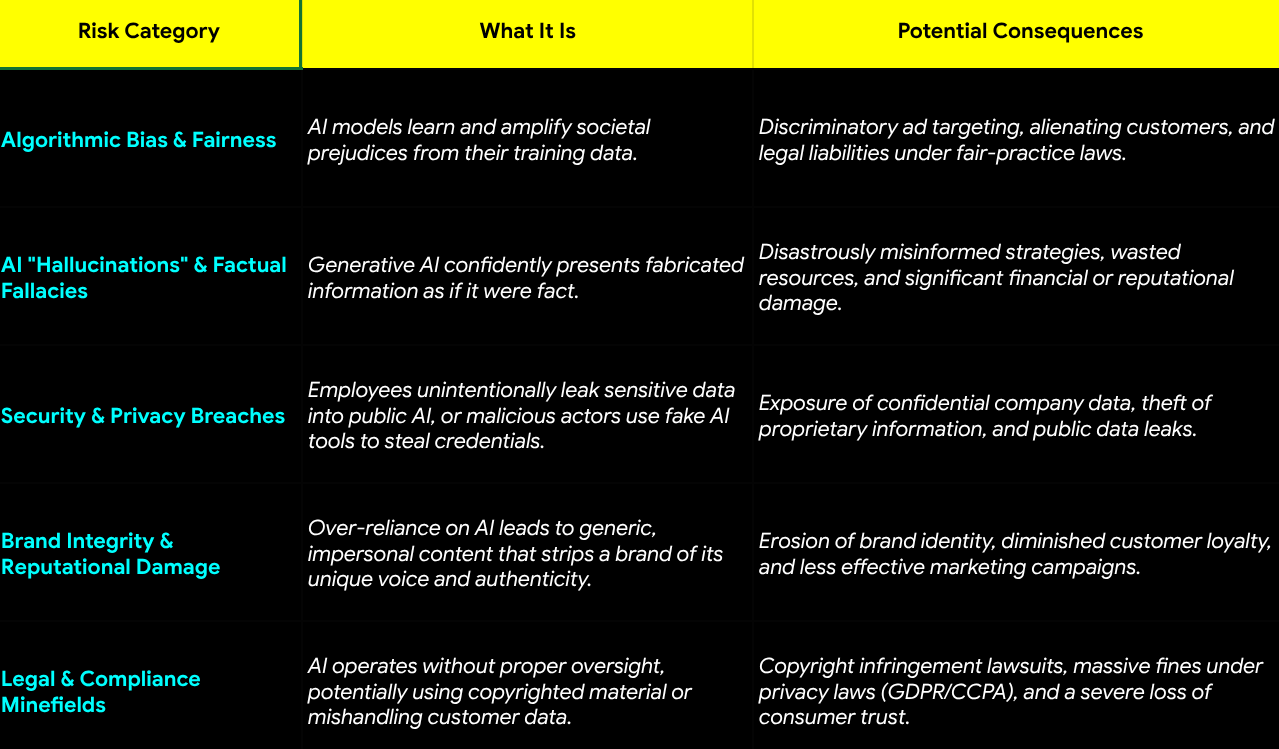
Let's be honest: AI is transforming marketing at lightning speed. Many businesses are now using entire teams of specialized AIs—or "Agentic Workflows"—that work together to launch campaigns, create content, and analyze data. But as we hand over the keys to these powerful systems, we're also inviting a whole new set of serious risks that can quietly snowball into a full-blown crisis.
To navigate this complex landscape, a robust governance framework is not just an ethical consideration—it's a strategic necessity.
The High Stakes of Unchecked AI Automation
The power of an AI marketing team lies in its interconnectedness, but this is also its greatest vulnerability. A mistake by one AI agent can be rapidly amplified by others, creating a domino effect of negative consequences.
Over the last few years, I have sat through numerous marketing discussions where teams would talk about incorporating AI into their campaigns. Now, the conversation has shifted entirely to building these complex agentic workflows. Here is my attempt to capture the different types of risks this new reality presents:
Do we have a solution? A Toolkit for Responsible Gen AI ??
The short answer is - Yes.
Google's Genetative AI Toolkit for Building Safer Gen AI Applications
Seeing these risks laid out can be intimidating, but they are not abstract problems. They are practical challenges that can be solved with an engineering-first mindset.
Google's Responsible GenAI Toolkit provides a framework and a set of tools designed to help developers build safer AI applications from the ground up.
At its core, a responsible Generative AI application follows a simple but powerful architecture: a central AI model protected by safeguards on both sides. An input safeguard checks the user's prompt before it reaches the model, and an output safeguard checks the model's response before it reaches the user. This entire system is supported by a feedback loop to capture failures and drive continuous improvement.
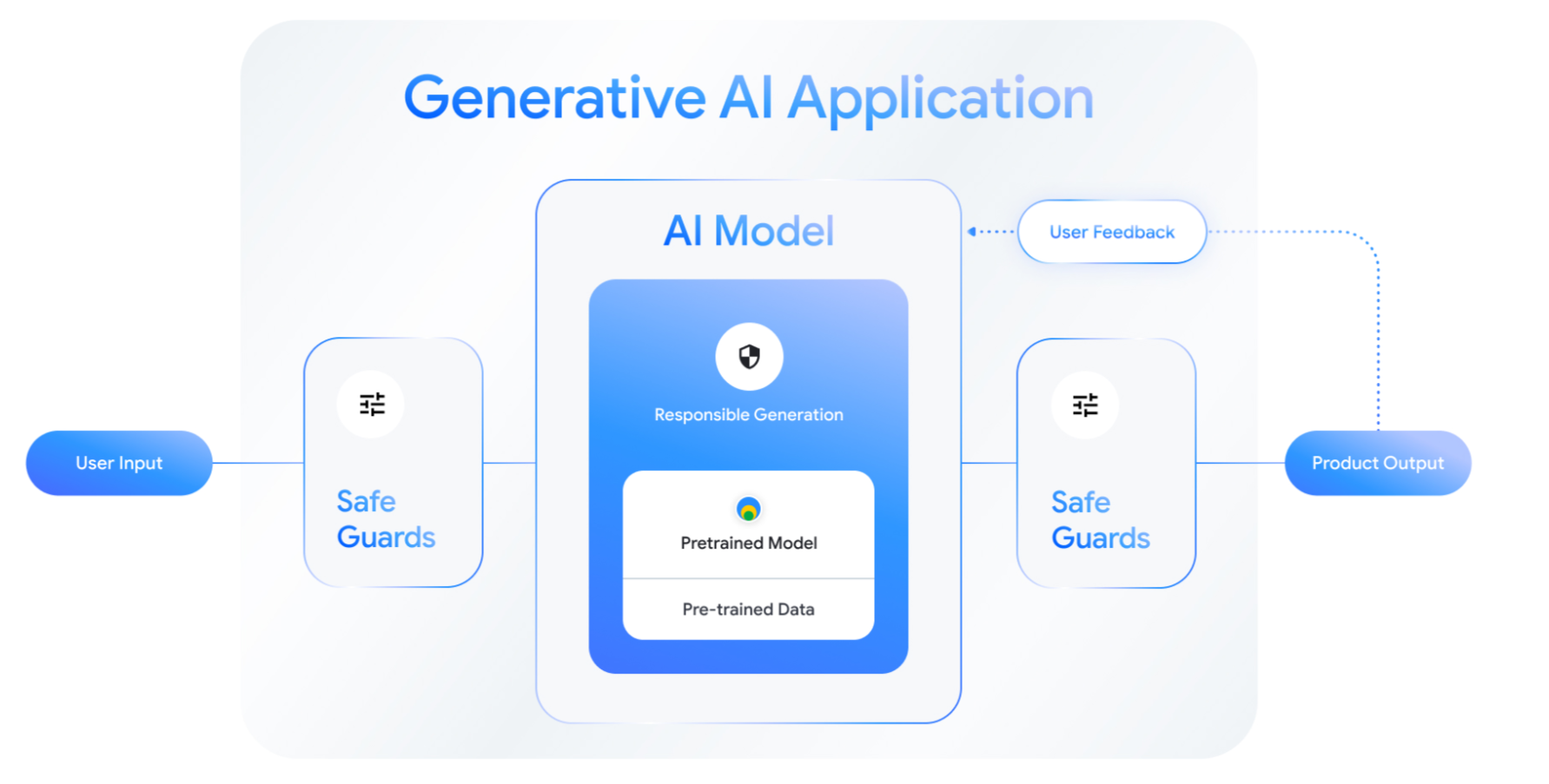
The toolkit organizes this process into three key stages: Align, Evaluate, and Protect.
Align: Understanding and Refining Model Behavior
To tackle nuanced risks like bias, you first need to understand what's happening under the hood.
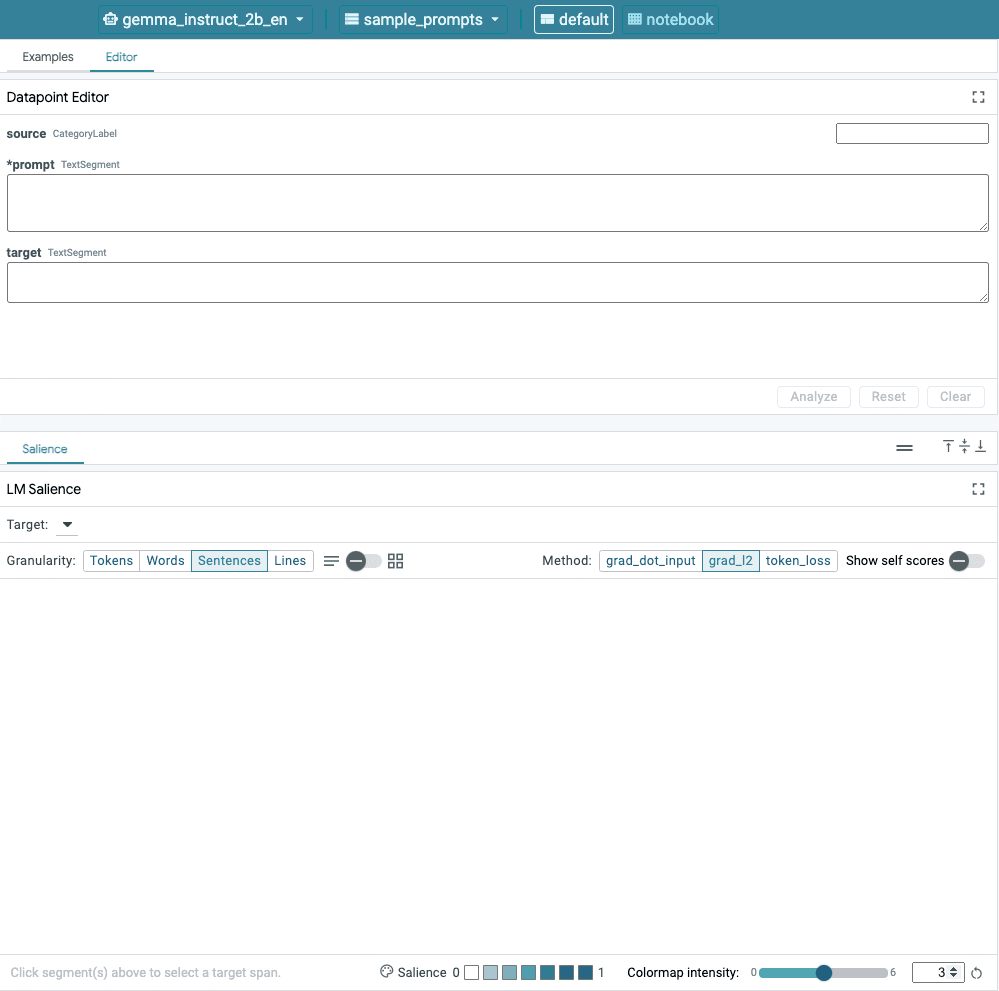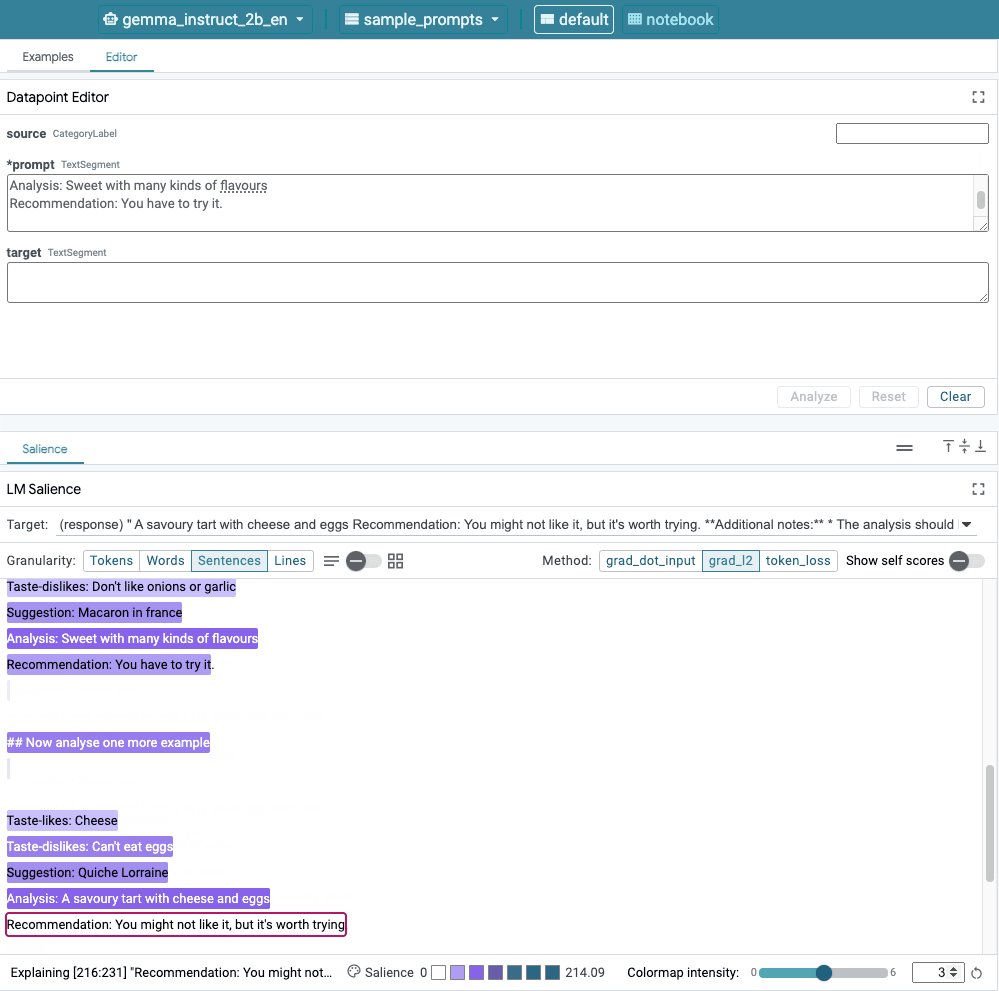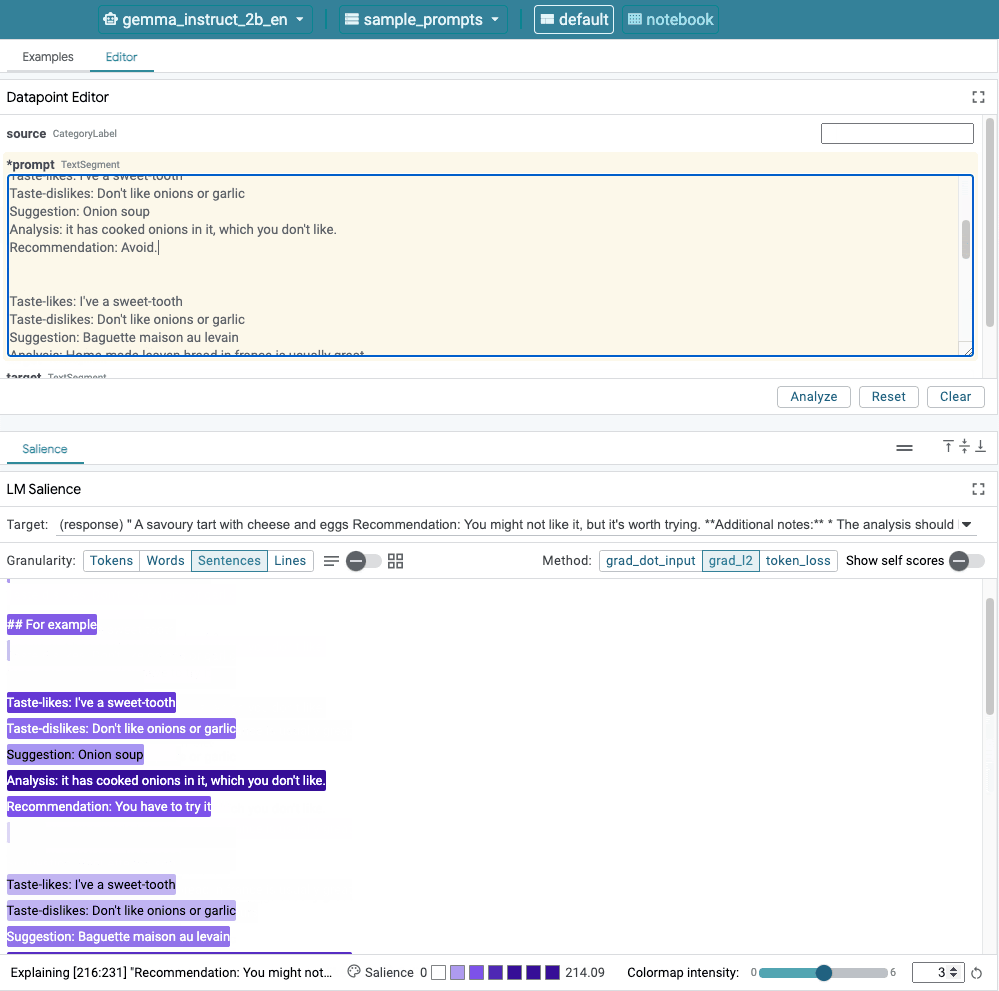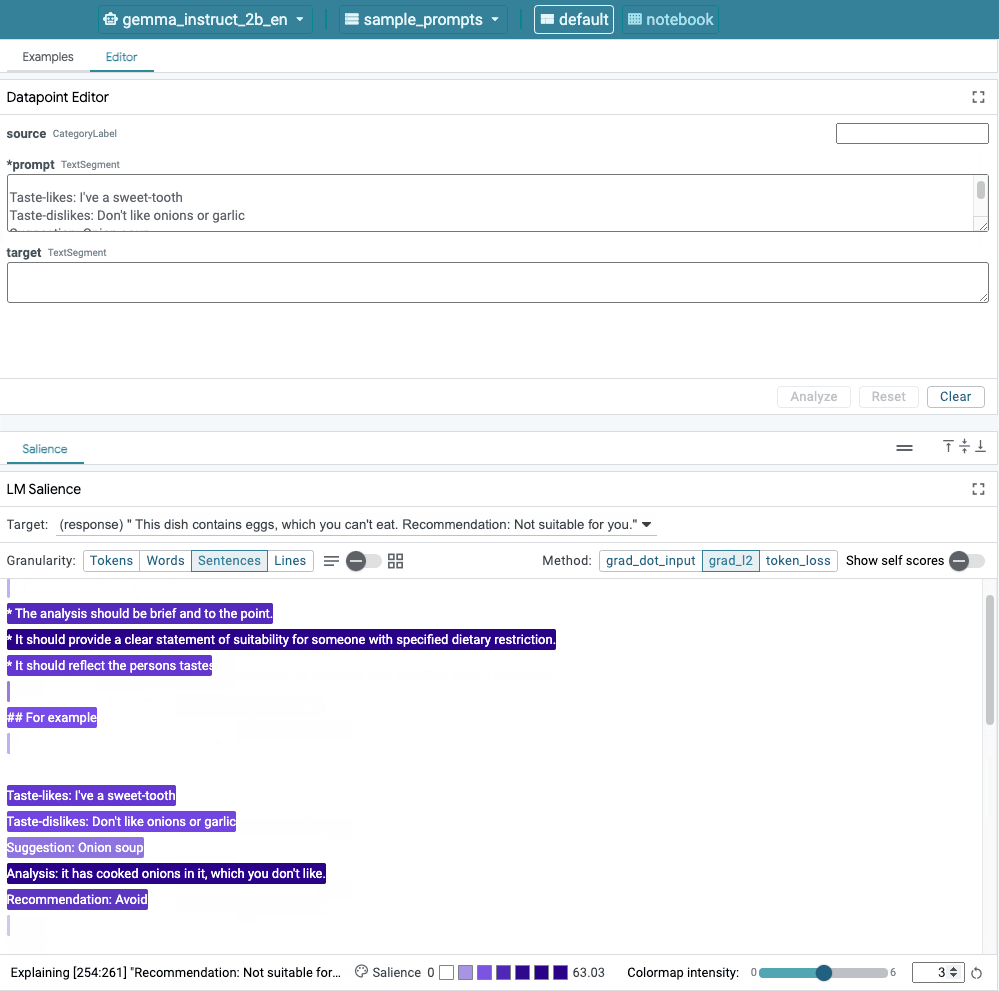
- The Learning Interpretability Tool (LIT): Think of LIT as a diagnostic tool for your AI. This open-source solution offers two key features. Sequence Saliency Analysis visually highlights which words in a prompt most influenced the model's output, helping you pinpoint the source of a biased statement. Counterfactual Generation allows you to swap out details in your prompt (like changing demographics) to test if the model behaves unfairly. It provides a clear, visual way to diagnose and address algorithmic bias.
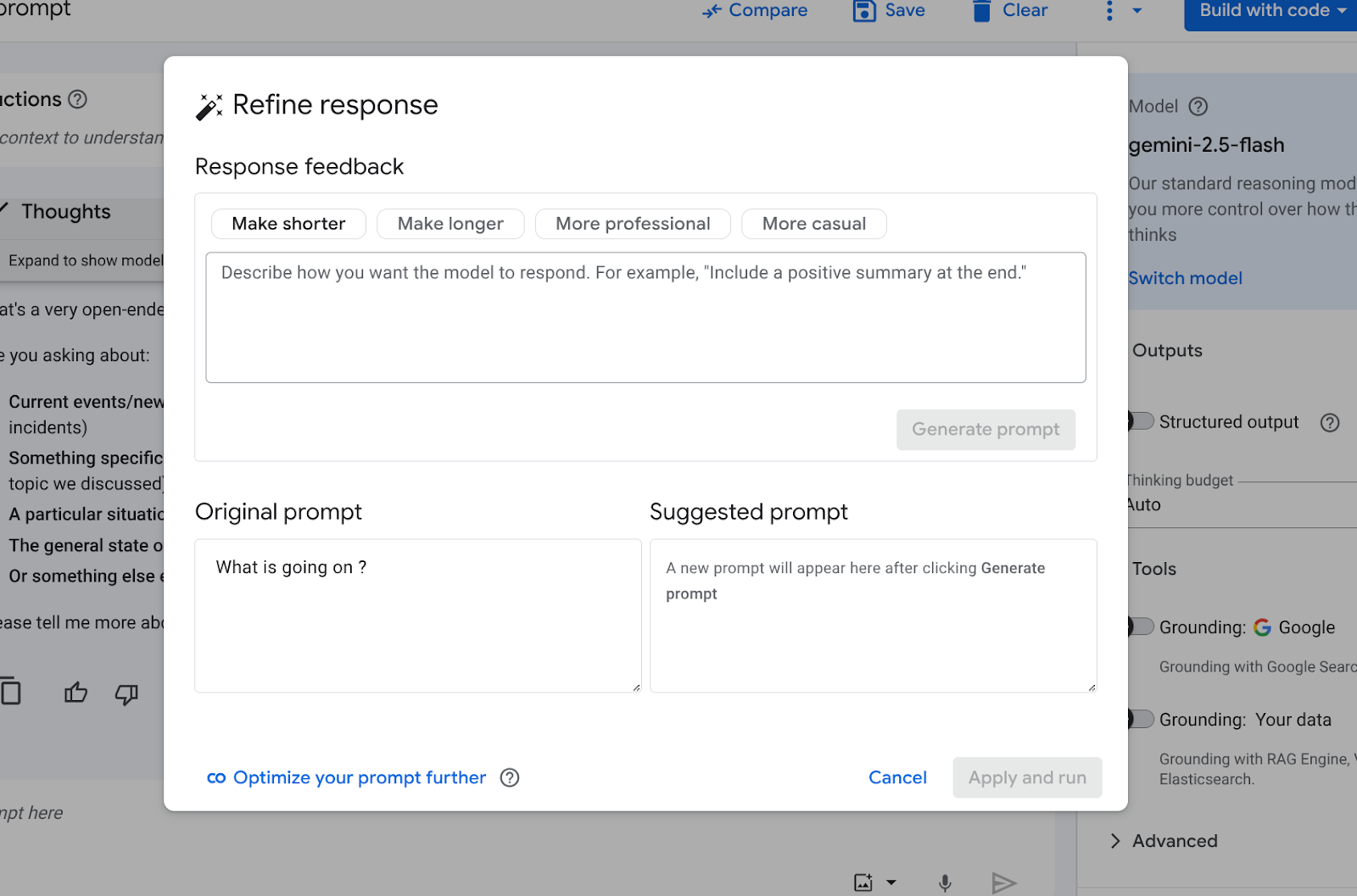
- Model Aligner: Once you can see what the model is doing, the next step is to steer it. Model Aligner uses a powerful "judge" LLM to help you refine your prompts. You can start with a basic instruction, critique the output (e.g., "This response needs to be more formal"), and the judge LLM will automatically rewrite the prompt to better achieve your desired result, promoting fairness and consistency.
Evaluate: Making Informed Decisions with Comparisons
The world of AI moves fast, and new models are released constantly. A key part of responsible development is ensuring that an "upgrade" is a true improvement.
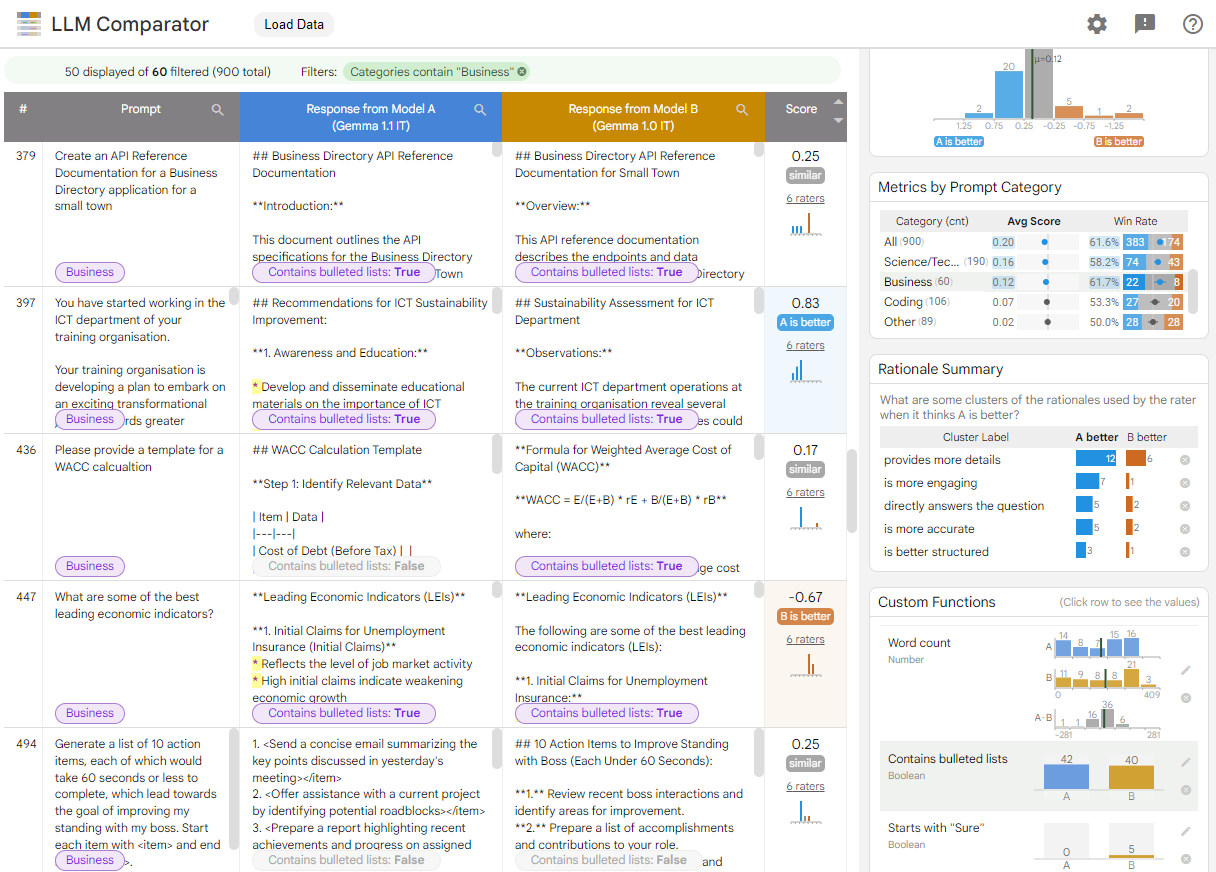
- The LLM Comparator: This is a straightforward but essential tool for making smart decisions. It provides a side-by-side comparison of how two different models respond to the exact same prompt. To scale up the evaluation, you can even use a third, more advanced LLM as an impartial "judge" to automatically determine which response is better and explain its reasoning. This helps ensure that when you switch to a new model, you don't inadvertently introduce new biases or brand safety issues
Protect: Building Policy-Driven Safeguards
This is your final line of defense, designed to filter harmful or unwanted content before it ever goes live.
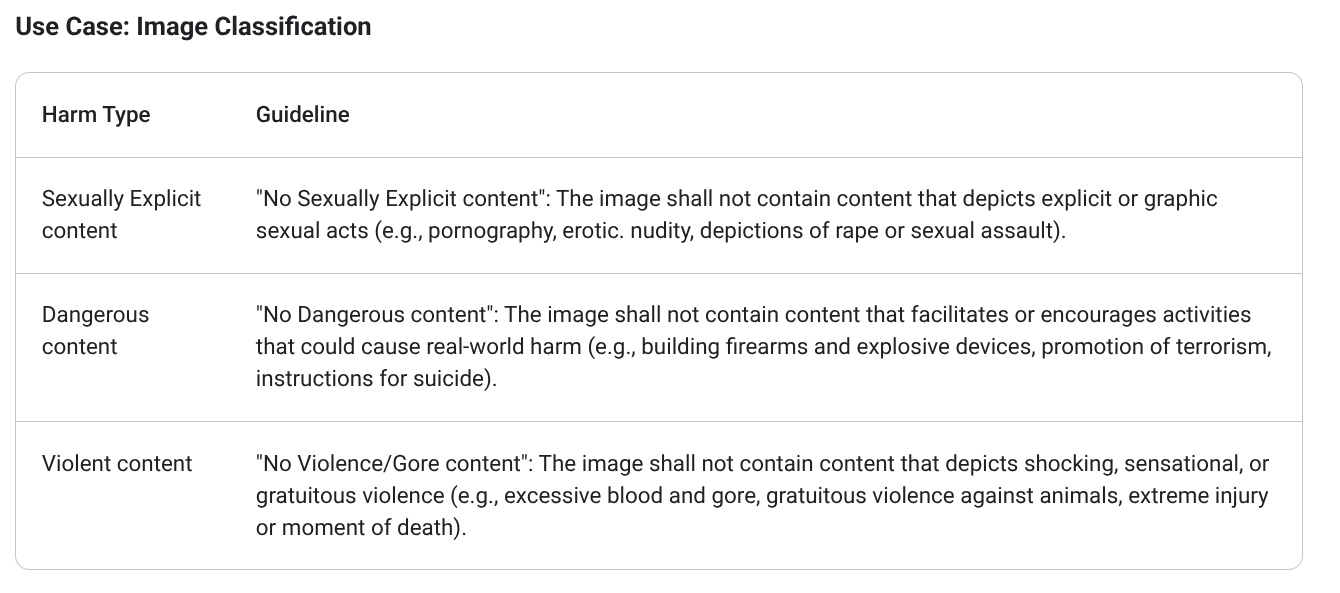
- ShieldGemma: Moving beyond generic safety filters, ShieldGemma offers precise, policy-driven content moderation. It's a specialized model fine-tuned to answer one simple question: Does a piece of content violate a specific policy, such as Harassment, Hate Speech, or Dangerous Content? Its job is to return a clear "yes" or "no," providing a decisive check against harmful output and protecting your brand's integrity.
- SynthID: To promote transparency in the wider ecosystem, SynthID embeds an imperceptible digital watermark directly into AI-generated content—whether it's text, images, or audio. This allows developers and the public to identify AI-generated content, a critical step in building a more trustworthy digital environment.

Lets Do a Quick Recap...
We started by acknowledging the incredible power of AI "Agentic Workflows" in marketing, but also the serious, interconnected risks they introduce—from bias and hallucinations to brand and legal damage. We then saw that these are not unsolvable problems. By adopting an engineering-first mindset, we can use a practical framework like the Align, Evaluate, and Protect lifecycle to build safer AI. We walked through specific tools that help us diagnose and steer our models (LIT, Model Aligner), make informed choices (LLM Comparator), and create robust safety filters (ShieldGemma), giving us a clear path to responsible AI development.
So what are the Key Takeaways??
- Governance is a Strategic Necessity: In the age of AI agents, robust governance is no longer optional. It's a core business function required to prevent reputational, financial, and legal crises.
- Adopt an Engineering-First Mindset: Don't treat AI safety as an afterthought. Address risks with the same rigor you apply to other engineering challenges, using dedicated tools and structured processes.
- The Lifecycle is Your Guide: The Align, Evaluate, and Protect framework provides a simple yet powerful roadmap. Use it to systematically de-risk your AI applications at every stage of development.
- From Using AI to Governing AI: The ultimate goal is to move beyond simply using AI as a black box. By actively understanding, testing, and controlling your AI systems, you can transform a source of significant risk into a safe, reliable, and powerful asset for your marketing team.
This is how you transform a source of significant risk into a safe, reliable, and powerful asset for your marketing team.
Thank you for taking the time to read through this!

